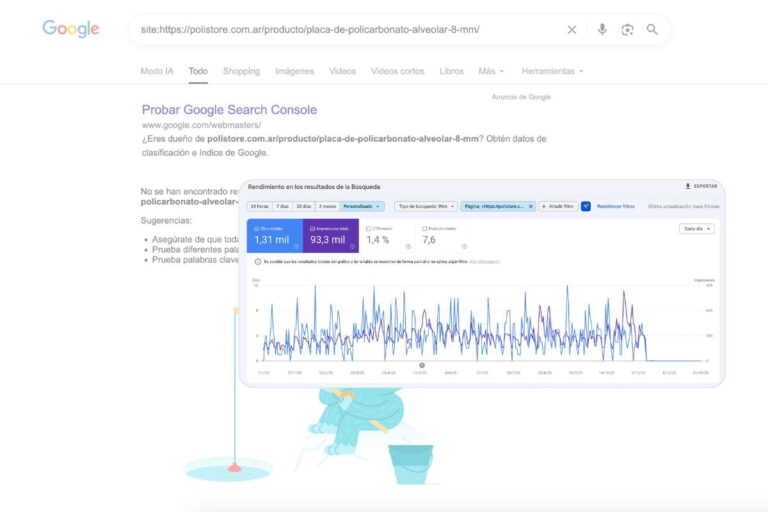
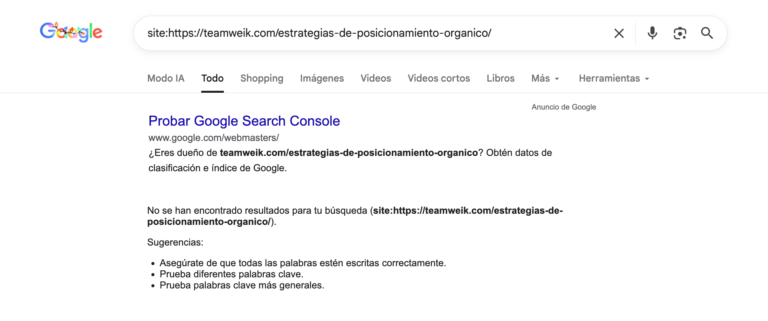
Si tenés un sitio web y notás que algunas páginas dejaron de recibir tráfico orgánico, es posible que Google las haya eliminado de su índice. Cuando esto ocurre, esas URLs dejan de aparecer en los resultados de búsqueda y, por lo tanto, pierden visibilidad.
Esto puede suceder por distintos motivos: problemas técnicos, configuraciones incorrectas dentro del sitio o incluso decisiones del propio algoritmo de Google. En este artículo vamos a analizar por qué Google puede desindexar páginas de una web, cómo detectar si está ocurriendo y qué podés hacer para recuperar la indexación.
¿Qué significa que Google desindexe páginas?
Los motores de búsqueda como Google siguen un proceso específico desde que descubren una página web hasta que la muestran en los resultados de búsqueda. Este proceso incluye varias etapas, entre ellas el rastreo, la indexación y el posicionamiento.
La indexación ocurre cuando el buscador encuentra una URL, analiza su contenido y la incorpora a su índice. A partir de ese momento, esa página puede aparecer en los resultados cuando un usuario realiza una búsqueda relacionada. Cuando hablamos de páginas desindexadas, pueden darse diferentes situaciones:
☞ La URL no ha sido detectada por los motores de búsqueda, por lo que nunca llegó a ser indexada.
☞ La URL fue descubierta pero tiene bloqueada su indexación, por ejemplo mediante etiquetas noindex o restricciones en el sitio.
☞ La URL fue encontrada e indexada, pero posteriormente fue eliminada del índice, lo que significa que ya no puede aparecer en los resultados de búsqueda.
Razones técnicas
En muchos casos, la desindexación de páginas no se debe a decisiones del algoritmo de Google relacionadas con la calidad del contenido, sino a problemas técnicos dentro del propio sitio web. Configuraciones incorrectas, cambios en la estructura del sitio o errores en la gestión de URLs pueden dificultar que los motores de búsqueda rastreen e indexen determinadas páginas.
Cuando esto ocurre, Google puede dejar de encontrar ciertas URLs o interpretar que ya no deben formar parte de su índice. A continuación, repasamos algunas de las causas técnicas más frecuentes que pueden provocar la desindexación de páginas dentro de un sitio web.
☞ Escaso de enlazado interno
El enlazado interno cumple un rol fundamental en el rastreo de un sitio web. Los motores de búsqueda descubren nuevas páginas y vuelven a rastrear las existentes siguiendo los enlaces internos entre las distintas URLs del sitio.
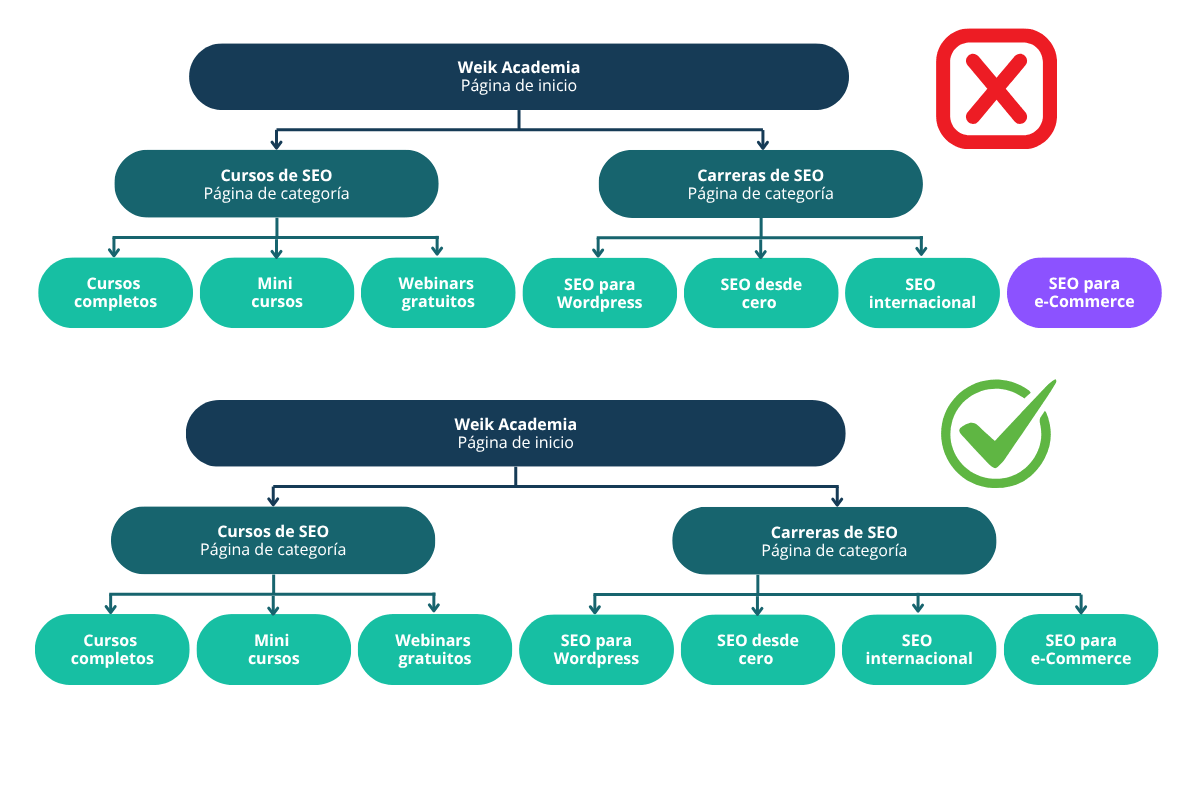
Si una página pierde estos enlaces, por ejemplo, después de una actualización de contenido o un rediseño, Google puede tener dificultades para volver a encontrarla. Con el tiempo, si la URL deja de ser accesible a través de la estructura interna del sitio, es posible que el buscador deje de rastrearla y termine eliminándola de su índice.
💡Solución recomendada: enlistar todas las URLs de tu sitio web que tiene contenido relacionado en las que podamos establecer una estrategia de enlazado interno efectivo.
☞ Incorporación de etiquetas meta robots
Las etiquetas meta robots permiten indicar a los motores de búsqueda cómo deben tratar una página específica. Si se incorpora la directiva noindex, se está indicando explícitamente a Google que esa URL no debe aparecer en los resultados de búsqueda.
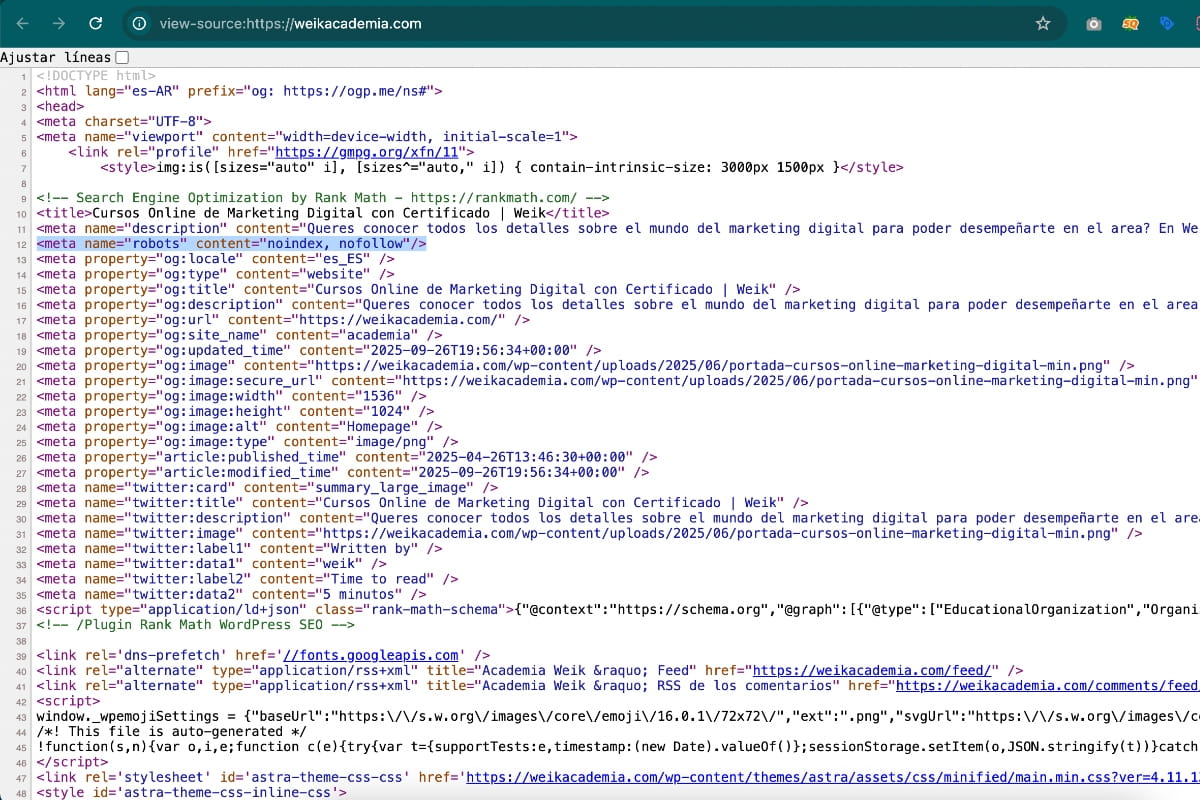
Este tipo de configuración puede añadirse de forma intencional, pero también puede aparecer por error durante cambios en el sitio, configuraciones de plugins SEO o ajustes en el CMS. Si una página importante incluye esta etiqueta, Google puede retirarla de su índice en el próximo rastreo.
💡Solución recomendada: revisar en el código fuente de la URL que se ha desindexado si hay una etiqueta meta robots “noindex”. En caso de que lo tenga se debe cambiar a “index”. En caso de no tenerla incluir la meta robots “index” para forzar las señales que le ofrecemos a los buscadores.
☞ Cambio del slug sin tratamiento SEO
Modificar el slug o la URL de una página sin aplicar un tratamiento SEO adecuado puede provocar la pérdida de indexación. Cuando una URL cambia y no se implementa una redirección 301 desde la dirección antigua hacia la nueva, Google puede interpretar que la página original ya no existe.
Esto suele derivar en errores 404 y en la eliminación de la URL antigua del índice. Además, si la nueva URL no es descubierta rápidamente mediante enlaces internos o sitemaps, puede tardar más tiempo en ser indexada nuevamente.
💡Solución recomendada: realizar la búsqueda con el comando site y la palabra clave para ver si hay una URL anterior con el contenido de la página con el nuevo slug para poder aplicar una redirección 301.
☞ Tu sitio web tiene muchas URLs
Los motores de búsqueda asignan a cada sitio web un presupuesto de rastreo o crawl budget, que determina cuántas páginas pueden rastrear durante un período determinado. En sitios con una gran cantidad de URLs,. por ejemplo, ecommerce o portales con filtros y parámetros, Google puede priorizar ciertas páginas y dejar otras sin rastrear durante largos periodos. Además, el buscador tiene limitaciones técnicas en la cantidad de contenido que procesa por página, lo que puede afectar la indexación de URLs con estructuras muy complejas o excesivamente pesadas.
💡Solución recomendada: realiza una limpieza de todas las URLs de tu sitio web que no son efectivas ni necesarias para poder eliminarlas asi los motores de búsqueda no pierden rastreo en páginas innecesarias. A su vez, bloquear el rastreo a URLs no relevantes.
☞ El usuario debe loguearse para acceder a la URL
Si una página solo puede visualizarse después de que el usuario inicia sesión, los motores de búsqueda no podrán acceder a su contenido. Los bots de rastreo de Google no completan procesos de autenticación ni interactúan con formularios de acceso, por lo que cualquier URL protegida por un sistema de login queda fuera de su alcance. Como resultado, estas páginas no pueden ser rastreadas ni indexadas, lo que impide que aparezcan en los resultados de búsqueda.
Razones de contenido
Además de los problemas técnicos, la calidad y características del contenido también pueden influir en la indexación de una página. Google busca mantener un índice útil para los usuarios, por lo que evalúa constantemente si una URL aporta valor real o si presenta señales que puedan afectar la experiencia de búsqueda.
Cuando el buscador detecta contenido duplicado, páginas con poco valor informativo o prácticas de optimización excesiva, puede decidir no indexar ciertas URLs o incluso eliminarlas de su índice con el tiempo. A continuación, repasamos algunas de las principales razones relacionadas con el contenido que pueden provocar la desindexación de páginas.
☞ Contenido duplicado con tu mismo sitio web
El contenido duplicado interno ocurre cuando varias páginas del mismo sitio web abordan exactamente el mismo tema o presentan textos muy similares. En estos casos, Google suele seleccionar solo una de las URLs como versión principal y descartar las demás para evitar mostrar resultados repetidos a los usuarios.
💡Solución recomendada: en caso de que haya más de una URL con el mismo contenido en tu web es importante que una la elimines y la redirecciones hacia la que va a quedar vigente. Caso contrario, lo que se puede realizar es cambiar el contenido de alguna de esas URLs asi los motores de búsqueda dejan de considerarlo como contenido duplicado.
☞ Contenido duplicado con otros sitios webs
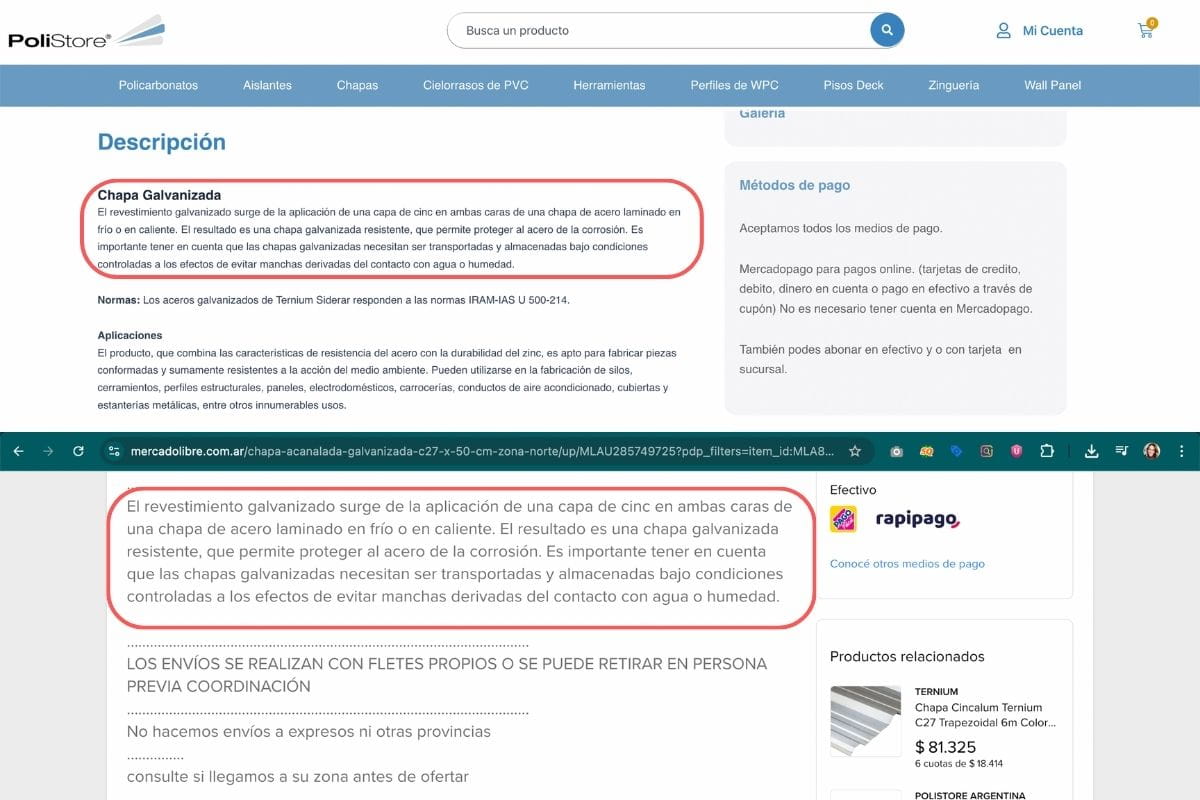
Otra causa frecuente de desindexación es la presencia de contenido que también aparece en otros sitios web. Esto es especialmente común en tiendas online que utilizan descripciones de productos proporcionadas por fabricantes o distribuidores.
Cuando Google detecta que el mismo contenido está publicado en múltiples dominios, suele priorizar la versión que considera más relevante o autoritativa. Las demás páginas pueden perder visibilidad o incluso ser excluidas del índice si el buscador considera que no aportan información adicional para el usuario.
☞ Thin Content
El thin content hace referencia a páginas que contienen muy poca información o que no aportan valor significativo al usuario. Esto puede incluir textos demasiado breves, contenido generado automáticamente o páginas creadas únicamente con fines de posicionamiento.
Si una URL tiene contenido insuficiente para responder adecuadamente a la intención de búsqueda del usuario, Google puede optar por no indexarla o eliminarla de su índice con el tiempo. Para evitarlo, es importante desarrollar contenidos completos, útiles y bien estructurados.
💡Solución recomendada: revisa las URLs que posicionan para las palabras clave que se oriente tu página desindexada para poder comprender qué bloques de contenido te hacen falta para mejorar las señales a los motores de búsqueda.
☞ Sobre optimización
La sobreoptimización ocurre cuando se aplican técnicas de SEO de forma excesiva dentro de una página, especialmente en el uso de palabras clave. Esto puede incluir la repetición artificial de la misma keyword, textos poco naturales o estructuras creadas únicamente para manipular el posicionamiento.

Los algoritmos de Google están diseñados para detectar este tipo de prácticas. Cuando una página presenta señales claras de sobreoptimización, el buscador puede reducir su visibilidad en los resultados o incluso optar por excluirla del índice si considera que el contenido no está pensado realmente para los usuarios.
💡Solución recomendada: leer el contenido de las páginas para poder comprender si la lectura queda robotizado o poco natural para poder optimizarlo nuevamente utilizando sinónimos.
☞ Backlinks comprados
Los enlaces externos siguen siendo un factor importante en el posicionamiento, pero su calidad es clave. Cuando un sitio obtiene una gran cantidad de backlinks artificiales —por ejemplo, enlaces comprados o provenientes de redes de sitios de baja calidad— Google puede interpretarlo como una práctica manipulativa.
Si el perfil de enlaces de una página genera señales de spam, el buscador puede aplicar diferentes medidas, que van desde la pérdida de posiciones hasta la eliminación de ciertas URLs del índice. Por esta razón, es recomendable priorizar estrategias de link building naturales y basadas en contenido de valor.
☞ Contenido oculto
El contenido oculto se refiere a textos o elementos dentro de una página que no son visibles para los usuarios, pero que sí pueden ser detectados por los motores de búsqueda. En algunos casos, esto se realiza para incluir palabras clave adicionales con el objetivo de mejorar el posicionamiento.
Google considera esta práctica una forma de manipulación del algoritmo. Cuando el buscador detecta contenido oculto, puede interpretar que la página intenta engañar a sus sistemas y decidir reducir su visibilidad o eliminarla del índice para proteger la calidad de los resultados de búsqueda.
💡Solución recomendada: lo que puedes realizar es un escaneo del código de la URL con el contenido visible de la página para poder evaluar si hay algún bloque o texto que se encuentra oculto por una cuestión estética o de spam.
¿Google desindexó páginas de tu sitio y no sabés por qué?
Detectar las causas de una desindexación no siempre es sencillo. En muchos casos intervienen factores técnicos, problemas de contenido o configuraciones SEO incorrectas que pueden pasar desapercibidos si no se realiza un análisis profundo del sitio.
En Team Weik somos especialistas en SEO y podemos analizar tu web de forma integral para identificar qué está afectando la indexación de tus páginas y proponemos soluciones concretas para recuperar su visibilidad en Google.
Si notaste que tu sitio perdió páginas en el índice o dejó de recibir tráfico orgánico, podemos ayudarte. Contactanos y realizaremos un análisis SEO de tu sitio web para detectar el problema y definir la mejor estrategia para recuperar tu posicionamiento.